
滚球app
2026-03-29 10:28 点击次数:163

【导读】就在昨天,ARC-AGI-3刚把全球顶尖大模子按在地上摩擦,扫尾一家名不见经传的公司却给出惊天音信:他们的AI在首日就取得了36.08%的收货!这匹黑马究竟靠什么撕开全球最难AI检修的铁幕?是真冲破,照旧另有秘要?
惊天大回转!
就在昨天,给AI的最难测试ARC-AGI-3横空出世,全球大模子整夜被血洗。
最强的顶流模子Opus 4.6,都只拿了0.2%分,简直惨不忍闻。与此同期,东说念主类却大猛提高,拿到了满分的好收货。
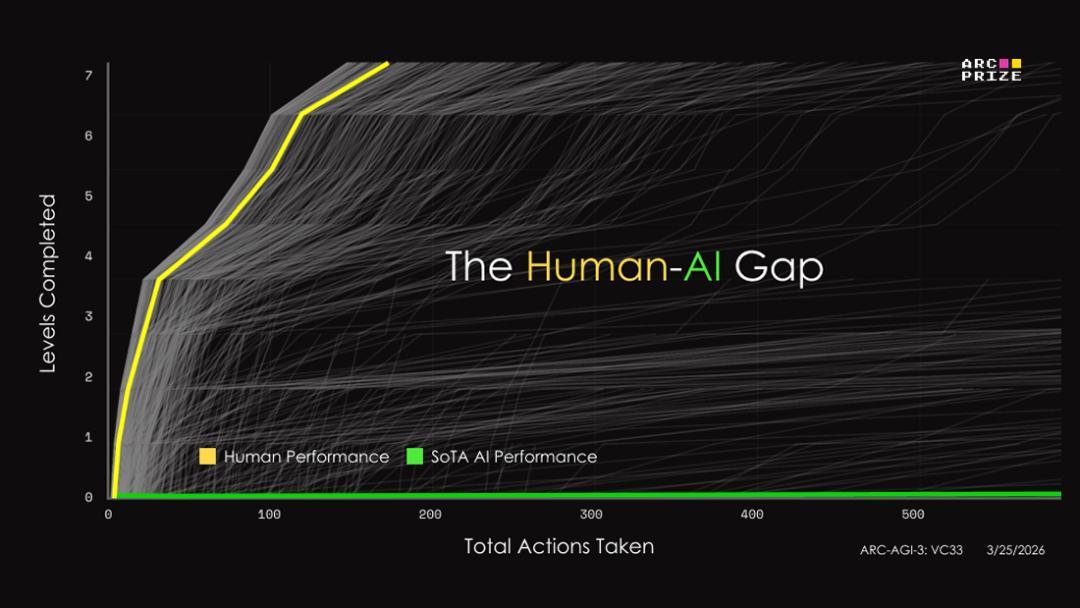
这让围不雅世界们大吃一惊:不管是老黄,照旧提议AGI宗旨发明东说念主,都以为如今咱们还是到达了AGI,难说念咱们确凿离AGI如斯远方?
出东说念主料想的是,短短一天内,ARC-AGI-3就被破解了!
就在刚刚,一家名为Symbolica的公司告示称:
使用Agentica框架,咱们在ARC-AGI-3测试中首日就取得了36.08%收货,全面碾压CoT模子基线。


182个关卡中,他们还是得手通关了113个。25个可用游戏中,他们完成了7个。
全球最难检修,被一把撕开缺口!
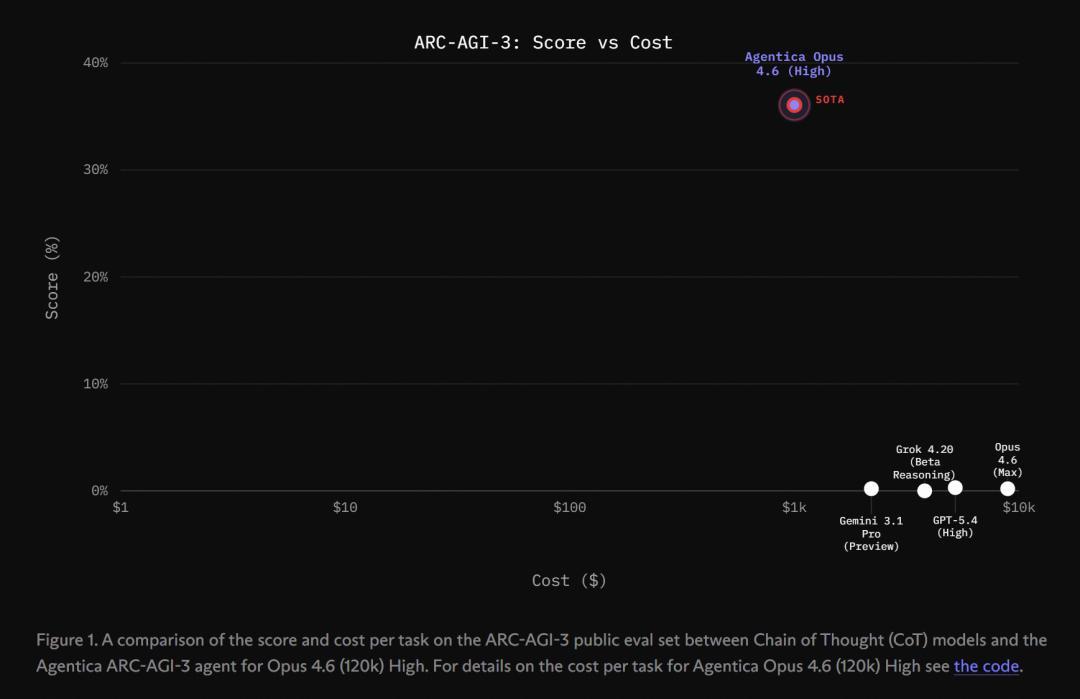
Symbolica首日爆冷,冲上36%
就在东说念主们还在为Opus 4.6那轸恤的0.2%得分唏嘘不已,以致启动怀疑「AGI是否仅仅大厂编织的幻梦」时,转机就以惊喜的情势驾最后。
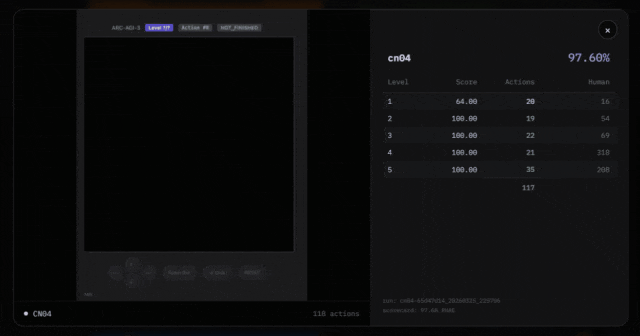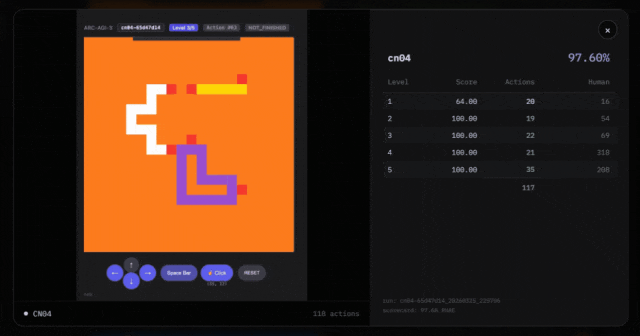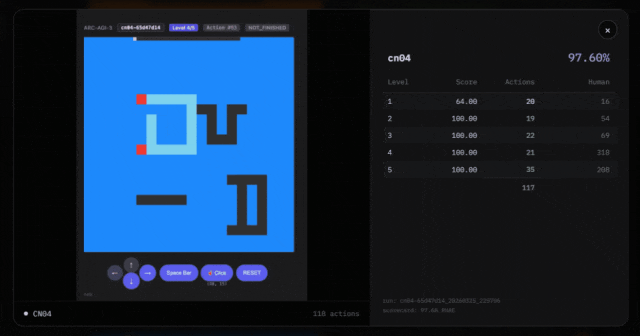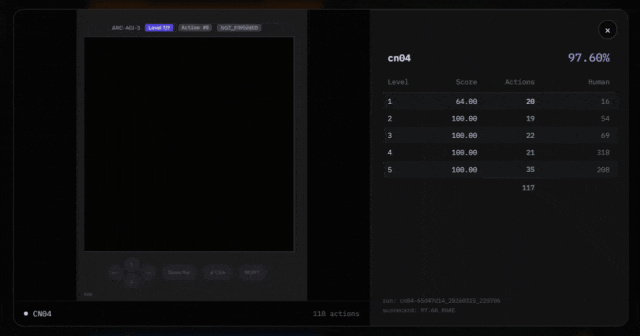
Symbolica的Agentica框架,为什么在ARC-AGI-3发布首日就能交出36.08%的惊东说念主收货单?
Agentica(Symbolica)基于Symbolica构建的ARC-AGI-3专用智能体系统。
要知说念,在ARC-AGI-3阿谁近乎变态的评分公式——(东说念主类步数 / AI步数)^2——眼前,大模子领头羊们还都在迷雾里原地打转呢。36.08%这个分数,简直是降维打击。

要意会Symbolica为什么能赢,最初要剖释Opus 4.6和GPT-5.4是怎样输的。
ARC-AGI-3与前两代最大的不同,就在于它不是「静态看图话语」,而是一个交互式黑盒游戏。
当一个基于隧说念LLM的智能体投入游戏,它最致命的弊端是:试图用空想代替逻辑,用模式匹配代替实验。
大模子在靠近未知环境时,会诈欺强盛的预教师学问库进行「脑补」。看到红色方块和蓝色线条,可能就会理猜测「推箱子」或者「水位平衡」,然后基于这个失误的假定猖獗输出CoT。
若是假定错了,它也不会停驻来反念念,而是会在失误的说念路上越跑越远,直到步数耗尽,得分归零。
ARC-AGI-3恰好针对AI的这些弊端,在100%可由东说念主类措置的环境中,揣度AI的三大才气:
随时候推移的技巧获取扫尾
疏淡反映下的长程筹画才气
跨多步、由劝诫驱动的适合才气
而Symbolica的Agentica框架,走出了一条完全不同的时刻旅途!
Agentica原生撑执多智能体架构,并具备设想上的可并行性。它会自动将复杂任务拆解为子问题,并将责任寄予给子智能体并行完成。
这意味着智能体八成保执高效鼓吹,开箱即用地更快完成任务!

Agentica是一个类型安全的AI框架,八成让LLM智能体与代码无缝集成:包括函数、类、举止对象,乃至统统这个词SDK。
此前,凭借强盛的长程推理任务,Symbolica就曾在ARC-AGI-2上取得SOTA收货,Agentica SDK为此立下了汗马之劳。
中枢窍门:Arcgentica RLM harness
从GitHub页面中,咱们在IDEA.md这个文献中,发现了Agentica框架的绝技——ARC-AGI-3智能体框架(Agent Harnesses)。
GitHub地址:https://github.com/symbolica-ai/ARC-AGI-3-Agents
Agent Harnesses,是最近的完满热词了,在Anthropic的官方博客和业内诸位大咖的计议中,它一直在被继续说起。
若是说2025年是智能体黄金时期的起初,那么2026年将聚焦于智能体框架(Agent Harnesses)。
智能体框架是一种围绕AI模子构建的基础才能,用于管理永劫候运行的任务,但它本人并不是智能体。
此次,Agentica从零启动意会游戏机制,并且在莫得任何特定游戏指示的情况下,措置多个关卡谜题。
这个基于Agentica SDK构建的Arcgentica RLM框架,有何颠倒之处?
最初,是游戏无关性。
ARC-AGI-3之是以难,是因为它剥离了统统当然语言指示。东说念主类能过关,是因为咱们领有物理直观。
为此,Agentica接受了最顶点的「游戏无关性」(Game-agnostic)策略。
智能体不知说念面貌代表什么,作为的作用是什么,或者顺利条目是什么,仅通过与游戏互动并不雅察变化来推断一切。
这种空缺情状,反而配置了它。
第二,是「统筹者 + 专科子智能体」的模式。
顶级统筹者,从叛逆直操作游戏,它将任务寄予给子智能体,积存学问,滚球app官网并决定下一步的步履。

专科子智能体包含:探索器、表面家、测试器妥协题机(explorers,theorists,testers,solvers)
若是它启动检察网格,其险阻文就会被像素数据填满,从而失去战略念念考才气。子智能体以狂妄的文本摘录时事陈述,而不是原始数据。
这种非中心化战略结构的精妙设想,让它袒护了Opus 4.6等模子中「消释个大脑既要看像素、又要记公法、还要贯串作为」的严重缺点。
第三,是它的「分享牵记」机制。
游戏期间,统统智能体分享一个 memories 数据库。子智能体在责任过程中会记载已说明的事实(场景布局、机制、顺利条目)和假定(并明确标志)。
新智能体在启动前会查询牵记,因此它们不错秉承集体学问。
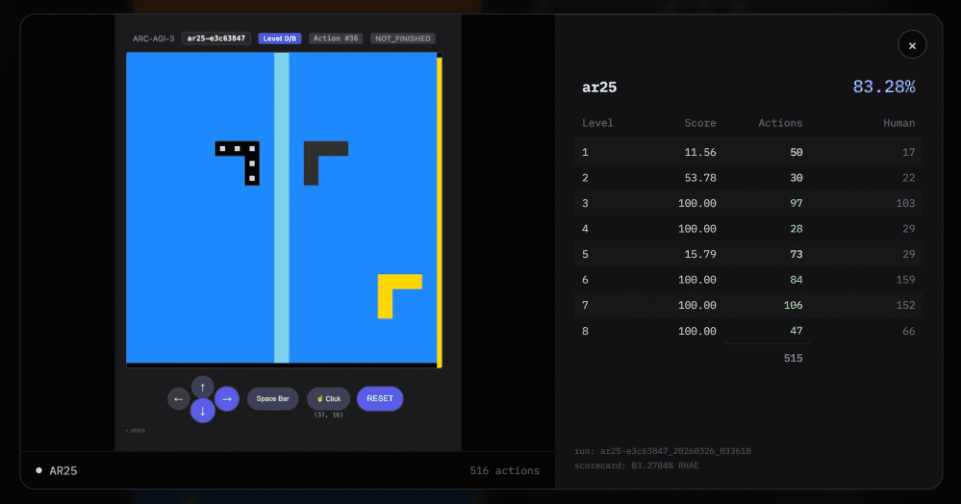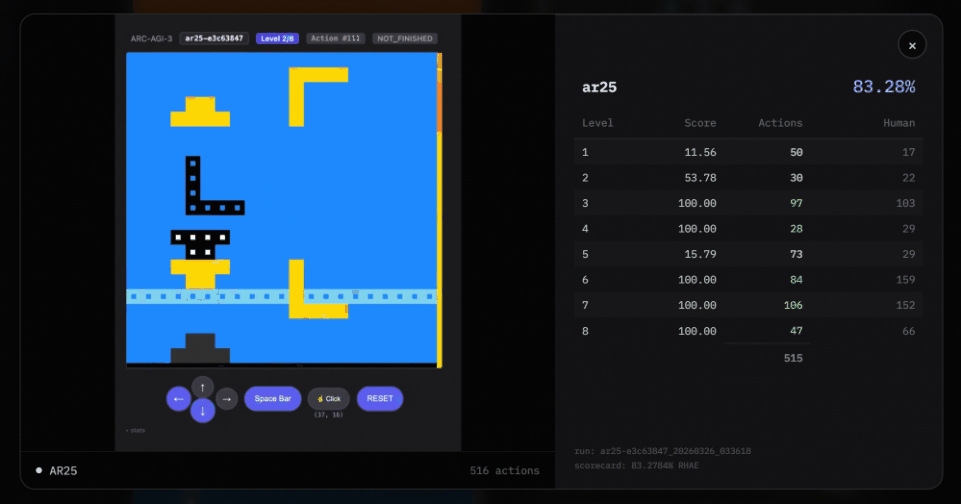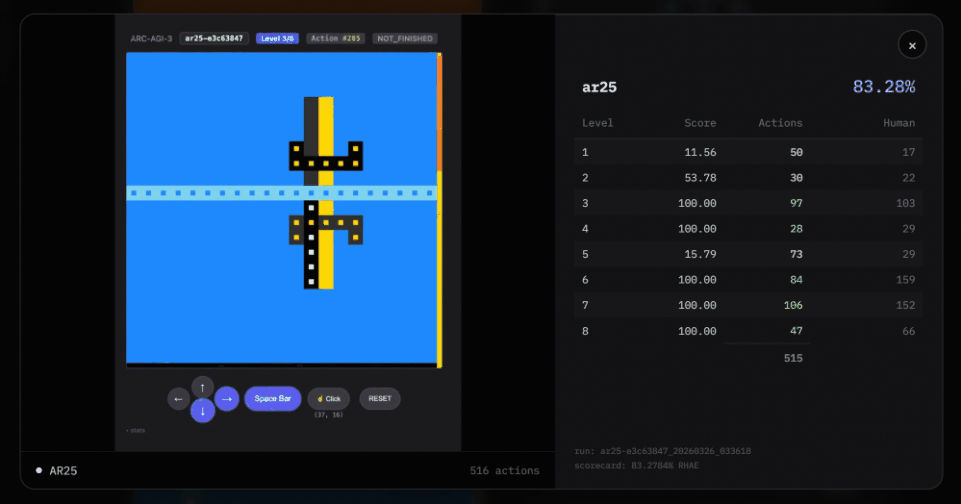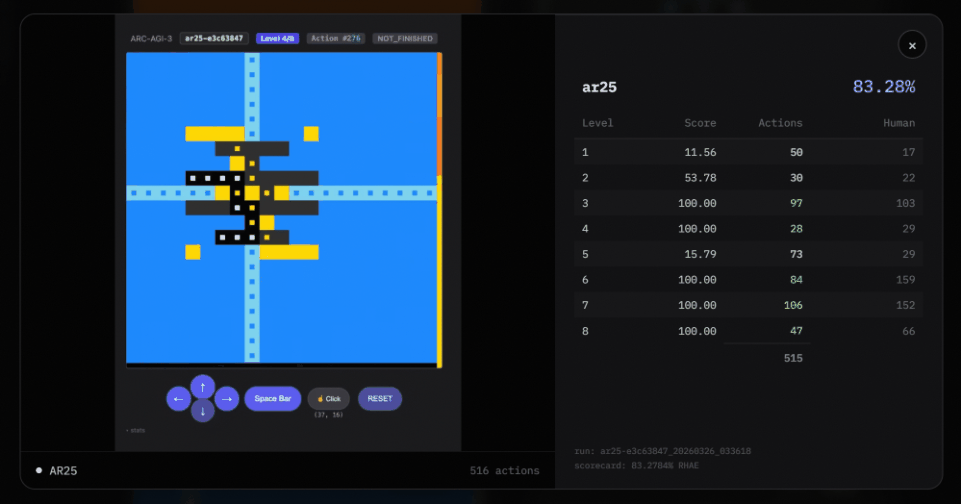
第四,是「关卡切换」机制。
关卡切换:当一个关卡被解出后,下一个关卡会在消释次操作中平直加载,复返的画面还是是新关卡。
只消当所相关卡都通关时,才会触发state=WIN;单个关卡的完成则通过不雅察 levels_completed 的增多来判断。
第五点,Agentica有严苛的步履预算管理,每一枚token都要花在刀刃上。
所相关卡的总操作次数是有限的(约 800 次)。改变器和会过 make_bounded_submit_action(limit) 为各个子智能体分派操作额度。系统会要求智能体幸免叠加操作,除非照实卡住。
并且,会优先进行有针对性的尝试,而不是暴力式的穷举探索。
另外,还有子智能体需要按需分派器用、改变器需要在复用与重启之间量度等规定。
要知说念ARC-AGI-3的官方定位,恰是强调「需要探索、感知 → 筹画 → 步履、牵记、指标获取与对皆等才气」。
而Agentica的单干涉完了策略,险些是对这些才气的「工程化拆解」:
探索(Exploration):由子智能体探索器(explorers)在作为预算下本质,尽量用差分不雅测索要「机制痕迹」。
筹办/推理(Planning/rule inference):由子智能体表面家(theorists)在「不允许submit_action」的管制下推导公法,裁减不测思意思作为破钞。
牵记(Memory): memories 数据库的显式化让跨关卡策略复用更平直,裁减「叠加学习」的作为与token 老本。
长程适配:关卡过渡由 levels_completed 检测,统筹者(orchestrator)决定沿用策略照旧重新投入探索轮回。
显著,这套机制与ARC-AGI-3的评分结构(后期关权重更高、扫尾普通处分)十分适配——它荧惑系统把作为花在「信息增益最高」的实验上,并尽快把策略挪动到更高权重关卡。
36.08%的高分,是否有水分?
不外,36%的收货无疑是刺眼的,但在经过ARC Prize官方考证之前,Symbolica的「爆冷」依然笼罩着几层迷雾。
Symbolica也承认,这一收货,当今莫得得到ARC-AGI-3组委会的官方认证。

材料中有一句相配要津的话:「unverified competition score」 (未劝诫证的收货)
Symbolica当今的收货是基于其自行搭建的环境,照旧严格复刻了官方的评估过程?这需要打一个问号。
并且,公布的得分明细表中,也有一些不寻常的细节。
比如,Symbolica指出「通过ARC-AGI-3 API获取的东说念主类基线分数标明,游戏cn04整个有6个关卡。这与通过API获取的相应游戏的关卡数目不符。」
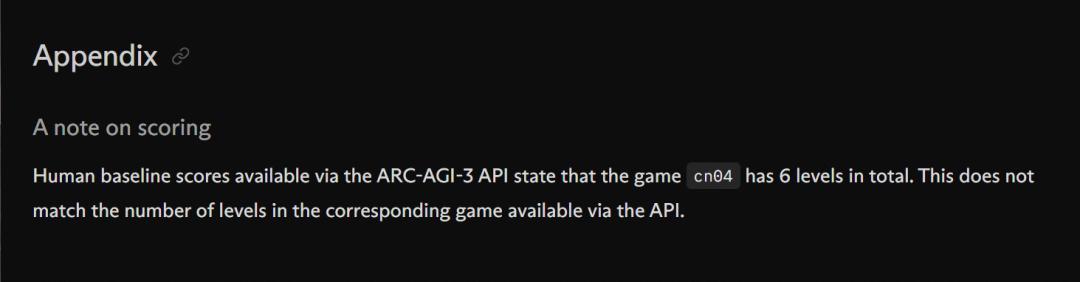
若是官方数据存在版块繁芜,那分数的有用性也就令东说念主质疑。
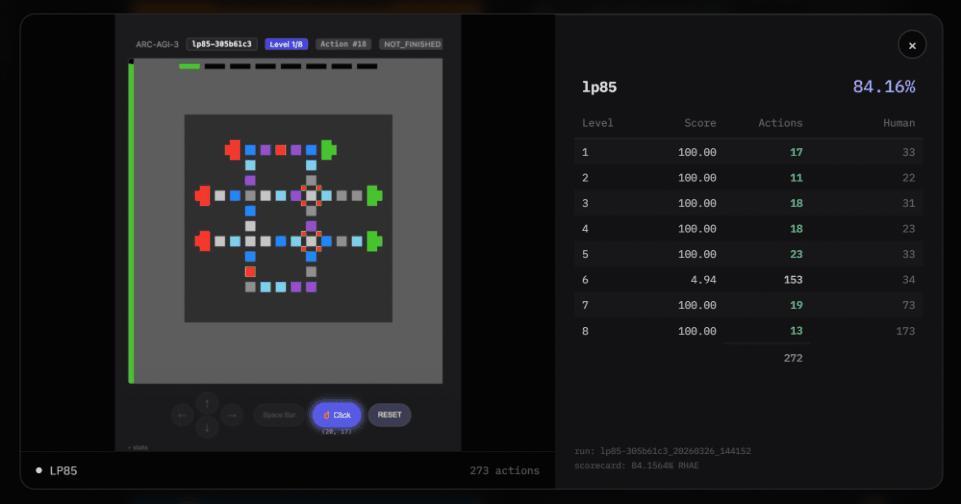
另外,在得分明细图中不错看出,像LP85、AR25等游戏得分极高(80%-97%),而SP80、BP35等游戏得分极低(0.2%-0.7%)。
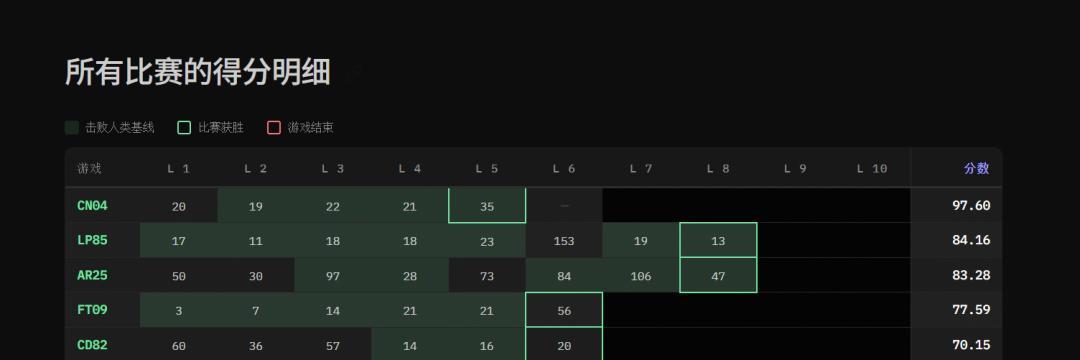

这种严重的南北极分化,是否是过拟合导致的?
毕竟,若是是的确的通用智能,应该在统统游戏上弘扬都相对平衡。
东说念主心所向:AGI的终极测试
昨天,ARC-AGI-3一出,就取得了万众瞩目,得到OpenAI、谷歌、xAI等多位AI大佬的招供。
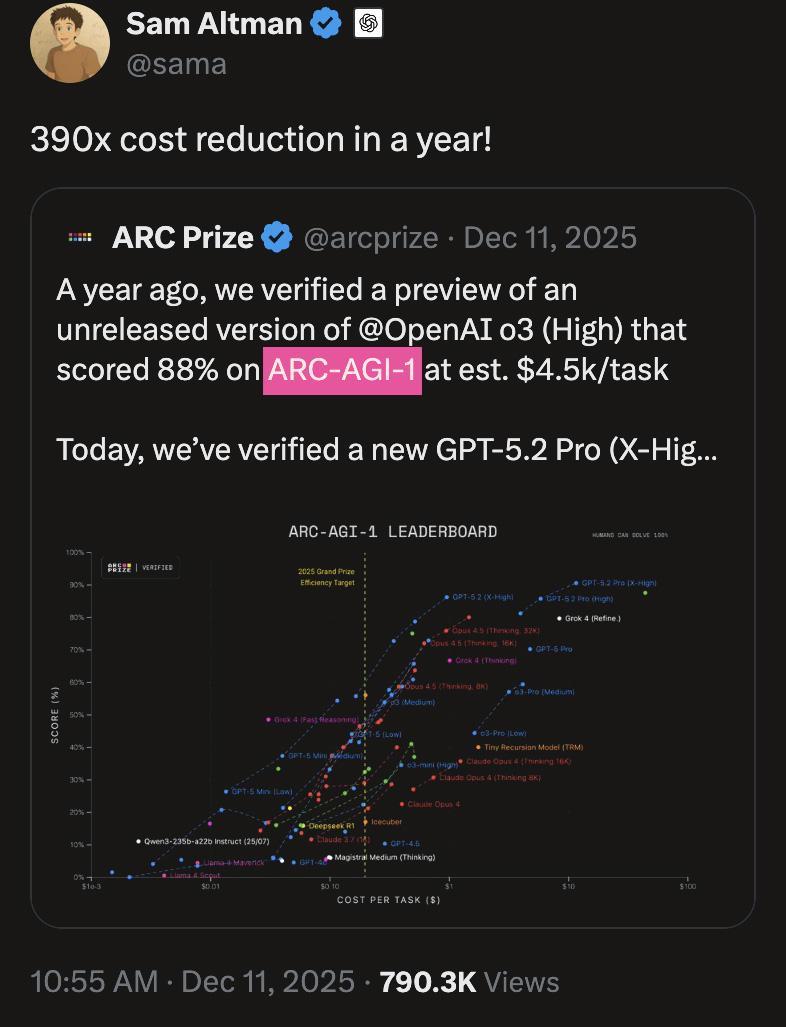
昨日,ARC-AGI-3追究发布时,奥特曼更是到现场力挺。


这个新的基准测试,被公以为永久通向AGI的「北极星」。
耐久以来,AI界的度量衡被锁死在静态基准的框架里。
然则,当OpenClaw这类「暴力进化」的AI智能体出现,行业显著急需一把剖解刀,去切开「主动式智能」的黑盒:比如深不见底的探索欲,毫秒级的感知方案,复杂的旅途筹画,以及近乎直观的指标对皆。

赛题:https://www.kaggle.com/competitions/arc-prize-2026-arc-agi-3/data
ARC-AGI-3祭出的考题,是在逼问AI:在完全生疏的公法眼前,你是否具备东说念主类那种综合与推理的本能?

ARC AGI 3时刻论述见下列长入:
https://arcprize.org/media/ARC_AGI_3_Technical_Report.pdf
在这里,每款游戏都需要智能体进行探索、意会并措置。满分(100%)意味着AI智能体八成像东说念主类通常高效地通关统统游戏。
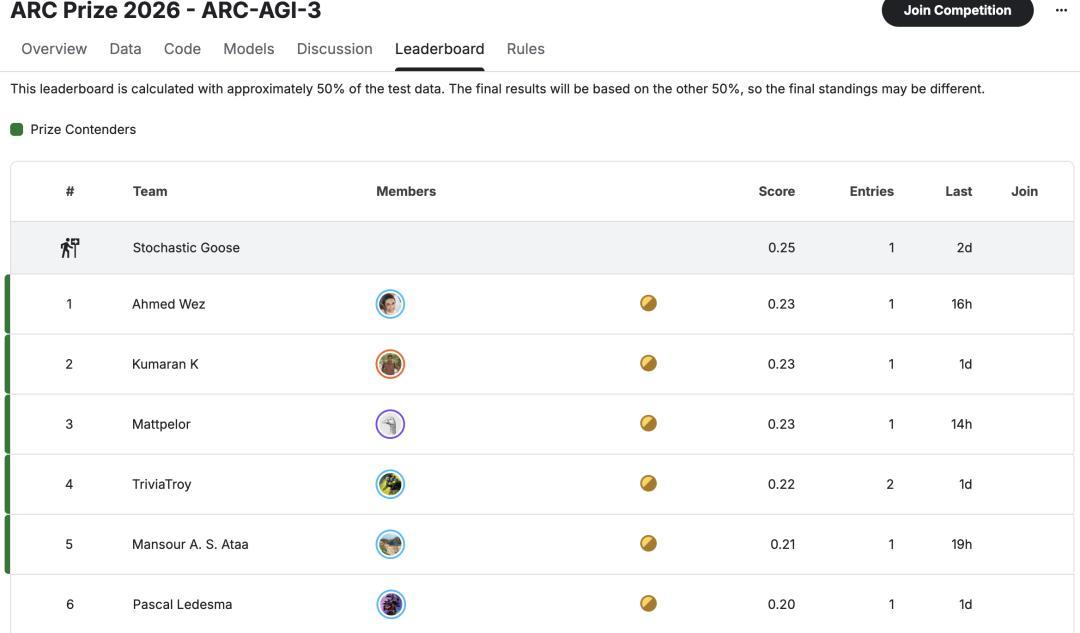
当今,最佳收货为0.25,也即是相配于东说念主类基线的25%。

ARC-AGI-3更伏击的意思意思,不是发布新的AI测试,不是草根逆袭AI巨头的爽文,而是开启了新智能体类型——智能体念念考。
碰巧的是,险些于ARC-AGI-3发布同期,林俊旸发表了对往时两年的追思,指出了相易的趋势:
自主性念念考(agentic thinking)将成为主流的念念考情势。
……
即使靠近极其贫穷的数学或编程任务,一个的确先进的(AI)系统也应有权进行搜索、模拟、本质、检查、考证和修正。

本体上,智能时事念念考,是模子通过步履来进行推理,关心的是模子在与环境交互的过程中能否执续取得进展。
他指出AI推理才气中枢问题从「模子能否念念考饱胀永劫候」转化为「模子能否以看护有用步履的情势进行念念考」。
ARC-AGI-3的背后目的,和林俊旸的念念考,无疑异曲同工了。
碰巧之处,就怕即是行业的下一个标的。
参考良友:
https://x.com/JustinLin610/status/2037116325210829168
https://github.com/symbolica-ai/ARC-AGI-3-Agents
https://www.symbolica.ai/blog/arc-agi-3滚球app
ag真人app官方网站入口 备案号:
备案号: